Posts
Wiki Contributions
Comments
Yep, you're totally right -- thanks!
Oh, one other issue relating to this: in the paper it's claimed that if is the argmin of then is the argmin of . However, this is not actually true: the argmin of the latter expression is . To get an intuition here, consider the case where and are very nearly perpendicular, with the angle between them just slightly less than . Then you should be able to convince yourself that the best factor to scale either or by in order to minimize the distance to the other will be just slightly greater than 0. Thus the optimal scaling factors cannot be reciprocals of each other.
ETA: Thinking on this a bit more, this might actually reflect a general issue with the way we think about feature shrinkage; namely, that whenever there is a nonzero angle between two vectors of the same length, the best way to make either vector close to the other will be by shrinking it. I'll need to think about whether this makes me less convinced that the usual measures of feature shrinkage are capturing a real thing.
ETA2: In fact, now I'm a bit confused why your figure 6 shows no shrinkage. Based on what I wrote above in this comment, we should generally expect to see shrinkage (according to the definition given in equation (9)) whenever the autoencoder isn't perfect. I guess the answer must somehow be "equation (10) actually is a good measure of shrinkage, in fact a better measure of shrinkage than the 'corrected' version of equation (10)." That's pretty cool and surprising, because I don't really have a great intuition for what equation (10) is actually capturing.
Ah thanks, you're totally right -- that mostly resolves my confusion. I'm still a little bit dissatisfied, though, because the term is optimizing for something that we don't especially want (i.e. for to do a good job of reconstructing ). But I do see how you do need to have some sort of a reconstruction-esque term that actually allows gradients to pass through to the gated network.
(The question in this comment is more narrow and probably not interesting to most people.)
The limitations section includes this paragraph:
One worry about increasing the expressivity of sparse autoencoders is that they will overfit when
reconstructing activations (Olah et al., 2023, Dictionary Learning Worries), since the underlying
model only uses simple MLPs and attention heads, and in particular lacks discontinuities such as step
functions. Overall we do not see evidence for this. Our evaluations use held-out test data and we
check for interpretability manually. But these evaluations are not totally comprehensive: for example,
they do not test that the dictionaries learned contain causally meaningful intermediate variables in the
model’s computation. The discontinuity in particular introduces issues with methods like integrated
gradients (Sundararajan et al., 2017) that discretely approximate a path integral, as applied to SAEs
by Marks et al. (2024).
I'm not sure I understand the point about integrated gradients here. I understand this sentence as meaning: since model outputs are a discontinuous function of feature activations, integrated gradients will do a bad job of estimating the effect of patching feature activations to counterfactual values.
If that interpretation is correct, then I guess I'm confused because I think IG actually handles this sort of thing pretty gracefully. As long as the number of intermediate points you're using is large enough that you're sampling points pretty close to the discontinuity on both sides, then your error won't be too large. This is in contrast to attribution patching which will have a pretty rough time here (but not really that much worse than with the normal ReLU encoders, I guess). (And maybe you also meant for this point to apply to attribution patching?)
I'm a bit perplexed by the choice of loss function for training GSAEs (given by equation (8) in the paper). The intuitive (to me) thing to do here would be would be to have the and terms, but not the term, since the point of is to tell you which features should be active, not to itself provide good feature coefficients for reconstructing . I can sort of see how not including this term might result in the coordinates of all being extremely small (but barely positive when it's appropriate to use a feature), such that the sparsity term doesn't contribute much to the loss. Is that what goes wrong? Are there ablation experiments you can report for this? If so, including this term still currently seems to me like a pretty unprincipled way to deal with this -- can the authors provide any flavor here?
Here are two ways that I've come up with for thinking about this loss function -- let me know if either of these are on the right track. Let denote the gated encoder, but with a ReLU activation instead of Heaviside. Note then that is just the standard SAE encoder from Towards Monosemanticity.
Perspective 1: The usual loss from Towards Monosemanticity for training SAEs is (this is the same as your and up to the detaching thing). But now you have this magnitude network which needs to get a gradient signal. Let's do that by adding an additional term -- your . So under this perspective, it's the reconstruction term which is new, with the sparsity and auxiliary terms being carried over from the usual way of doing things.
Perspective 2 (h/t Jannik Brinkmann): let's just add together the usual Towards Monosemanticity loss function for both the usual architecture and the new modified archiecture: .
However, the gradients with respect to the second term in this sum vanish because of the use of the Heaviside, so the gradient with respect to this loss is the same as the gradient with respect to the loss you actually used.
I believe that equation (10) giving the analytical solution to the optimization problem defining the relative reconstruction bias is incorrect. I believe the correct expression should be .
You could compute this by differentiating equation (9), setting it equal to 0 and solving for . But here's a more geometrical argument.
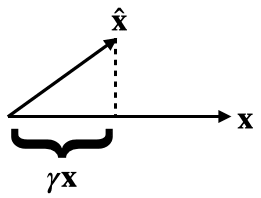
By definition, is the multiple of closest to . Equivalently, this closest such vector can be described as the projection . Setting these equal, we get the claimed expression for .
As a sanity check, when our vectors are 1-dimensional, , and , we my expression gives (which is correct), but equation (10) in the paper gives .
Great work! Obviously the results here speak for themselves, but I especially wanted to complement the authors on the writing. I thought this paper was a pleasure to read, and easily a top 5% exemplar of clear technical writing. Thanks for putting in the effort on that.
I'll post a few questions as children to this comment.
I'm pretty sure that you're not correct that the interpretation step from our SHIFT experiments essentially relies on using data from the Pile. I strongly expect that if we were to only use inputs from then we would be able to interpret the SAE features about as well. E.g. some of the SAE features only activate on female pronouns, and we would be able to notice this. Technically, we wouldn't be able to rule out the hypothesis "this feature activates on female pronouns only when their antecedent is a nurse," but that would be a bit of a crazy hypothesis anyway.
In more realistic settings (larger models and subtler behaviors) we might have more serious problems ruling out hypotheses like this. But I don't see any fundamental reason that using disambiguating datapoints is strictly necessary.
(Edits made. In the edited version, I think the only questionable things are the title and the line "[In this post, I will a]rticulate a class of approaches to scalable oversight I call cognition-based oversight." Maybe I should be even more careful and instead say that cognition-based oversight is merely something that "could be useful for scalable oversight," but I overall feel okay about this.
Everywhere else, I think the term "scalable oversight" is now used in the standard way.)
I think this is cool! The way I'm currently thinking about this is "doing the adversary generation step of latent adversarial training without the adversarial training step." Does that seem right?
It seems intuitively plausible to me that once you have a latent adversarial perturbation (the vectors you identify), you might be able to do something interesting with it beyond "train against it" (as LAT does). E.g. maybe you would like to know that your model has a backdoor, beyond wanting to move to the next step of "train away the backdoor." If I were doing this line of work, I would try to some up with toy scenarios with the property "adversarial examples are useful for reasons other than adversarial training" and show that the latent adversarial examples you can produce are more useful than input-level adversarial examples (in the same way that the LAT paper demonstrates that LAT can outperform input-level AT).